(First created: 12/08/2024 |Personal Opinion)
As the loner level-headed person among the GenAI frenzies at where I work, I question a lot on GenAI use cases beyond domains of texts and code. But that doesn’t mean I’m a doubter of the technology. Quite the contrary, my team laid the GenAI fiber-optic cables to our doorstep right after ChatGPT was announced in 2023 and built a GenAI Gateway for last yard delivery to foster GenAI innovations two months later.
![]()
While the design and implementation choices depend on your engineering reality, I hope a reference functional and architectural model of an idealized GenAI Gateway would be helpful to you.
1. For the impatient
Let’s start with the overall system components of GenAI Gateway and the lessons learned along the way building it.
1.1 ICOM functional model of GenAI Gateway
Following the IDEF0 modeling framework, below are the input, control, output and mechanisms of GenAI Gateway functionalities:
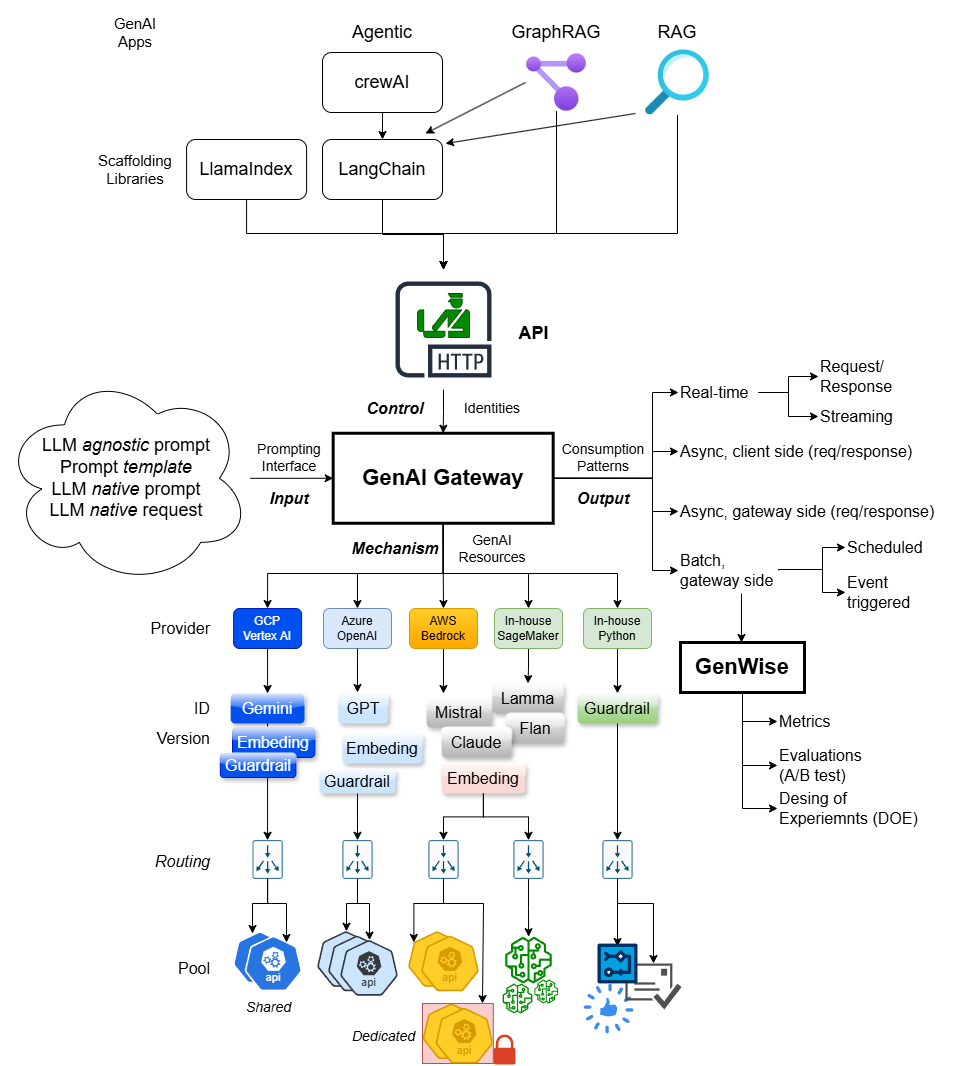
Read on for details of each component but three concepts are worth highlighting right off the bat:
- Model Spec. Specification of the identity and operational requirements for the model.
- Prompt Spec. Specification of the prompt to GenAI models.
- Native Interface. Native interface expected by the backend vendor models.
- Abstract Interface. Vendor and model agnostic interface provided by GenAI Gateway with which you code your application once and target all vendors and models.
1.2 Lessons learned
- Build don’t Buy. Each cloud providers have their own offering of GenAI Gateway but they’re genetically myopic: GCP is limited to Gemini, Azure to OpenAI. AWS, the least innovative in the GenAI space ironically has the most generic GenAI interface due to their catchup effort in taking and abstracting over open source and commercial LLMs. But as an enterprise consumer, you need to abstract over ALL vendors and ALL LLMs and you don’t want to fall victim to cloud vender’s up-selling.
- Build support for native interfaces first. Build a /direct-invocation endpoint first which enables practitioners to consume any models from any vendors in their native syntax. Then build the abstraction layer over vendors and models. The former offers speed to innovation and ultimate flexibility and the latter client code stability, effortless switch and ease of use.
- Solve for scalability next. App ID level token rate limit, dedicated throughput pool, Bring Your Own Models & Metrics (BYOM&M) and Buy Your Own Throughput (BYOT) process and mechanisms… You need all these to control the bad actors, protect and provide for the good actors, and kick the balls back to use case teams to deflect their complaints such as “it takes too long to onboard our models” and “we’re constantly throttled!”.
- Build your own abstract interface rather than relying on vendor or open-source frameworks such as LangChain. Your abstraction over GenAI should be business and task oriented and it should be informed by the common patterns emerged over time from your GenAI use cases.
- Delegate don’t build. Non business value-add features such as token rate limiting should be pushed down and delegated to vendor layer. They’re tricky to build in-house and too common a feature for the vendors not to offer.
If I have the chance to go over the GenAI journey again, above would be the rough order of endeavors I would go about building a GenAI Gateway.
2. Anatomy of GenAI System
Gateway, LLM vendors, and LLMs… Prompt, parameters and requests…There are multiple layers of abstractions and multiple components in each layer’s interface.
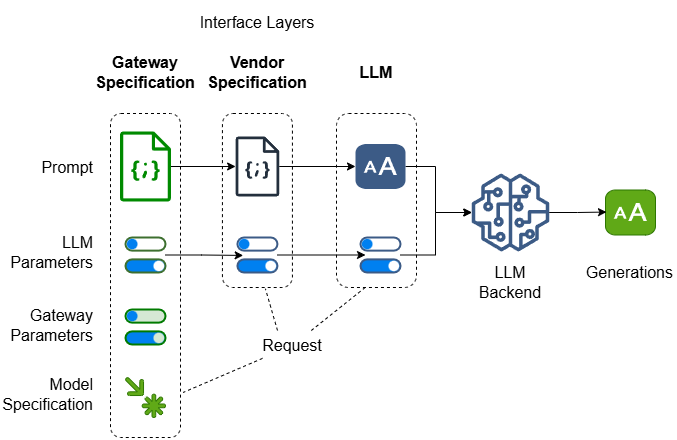
2.1 LLM prompt, vendor and Gateway prompt specification
In the beginning, LLMs are just autoregressive next token generators which take a piece of unstructured text (prompt) and generate another piece of unstructured text that continues and completes the prompted text. I call this LLM prompt and important thing worth repeating: it’s a piece of unstructured text. Most open-source LLMs still follow this text-in-text-out interface.
Commercial LLM vendors then introduced structured “prompt specification” in the form of JSON with which itemized and categorized information about LLM prompt may be specified. Note this structured JSON is NOT the actual prompt the LLM gets to continue and complete, rather it’s just a container with a vendor specific structure to hold information with which vendor may use to assemble the unstructured LLM prompt.
To abstract over the structural differences among different vendor’s prompt specification, GenAI Gateway’s prompt specification needs to be either:
- One of the vendor’s prompt specifications, -OR-
- Yet another prompt specification at a higher abstraction level.
Either way, GenAI Gateway’s prompt specification needs to be translated to vendor’s prompt specification which further need to be translated to the actual LLM prompt.
2.2 Model Parameters
Vendor defined parameters to affect the behavior of the backend LLM. A simple dictionary of key value pairs which is pass through as a dictionary or mapped to a set of query parameters per the backend LLM syntax.
2.3 Gateway Parameters
Self-defined set of parameters to affect GenAI Gateway’s behaviors. For example:
- return-assembled-request. Useful debug flag to return as part of the response the actual request assembled by GenAI Gateway.
- token-usage. Return as part of the response the input and output token usage.
- time-metrics. Return the overall and a breakdown of time spent within the boundaries of GenAI Gateway. For example, time spent authenticate and authorize the request and time spent calling the backend LLM endpoint.
- response-filters. List of JSON paths/fields to pick out of the response JSON.
2.4 Model Specification
A set of attributes specifying different aspects of the model.
- Vendor. Such as ‘Azure OpenAI’ or ‘AWS Bedrock’. ‘SageMaker’, ‘Vertex AI’ and ‘Python’ maybe used to signify internally deployed endpoints or Python classes.
- ID. The official ID of the models defined by the vendors, or internal model IDs defined in the model registry. See Azure OpenAI and AWS Bedrock documentation for their model IDs.
- Version. The official versions of the models defined by the vendors.
- Type. (Optional) Type of the model. “text”, “image”, “embeddings”, “guardrail”…
- Task. (Optional) GenAI task the model is used to accomplish.
- endpoint-type. (Optional) Invocation type of the model endpoint.
- interface-type. (Optional) Model interface type.
- Pool. (Optional) The identifier of the throughput pool for the model. Could be provisioned units or the common prefix for a set of endpoints.
Each model attributes serves different purposes:
| Purpose | Model Attributes | Description |
|---|---|---|
| Identity |
|
What model to use? |
| Routing, functional |
|
What client from the vendor SDK to use? `text`/`generation` and `audio`/`transcription` may resides in different packages of the vendor SDK. |
| Routing, interface |
|
What GenAI Gateway endpoint to use? For a `text`/`generation` request, GenAI Gateway `/batch` endpoint needs to know whether it’s in native format or not to route to the correct GenAI Gateway endpoint. |
| Routing, invocation style |
|
choose between `sync` or `async` versions of the model endpoint |
| Routing, throughput pool |
|
choose among different throughput pools for the model endpoint |
A specific model spec can be mapped to a backend endpoint or endpoint pool.
2.5 Request
A JSON consists of all or a subset of below components:
- Model specification
- Model parameters
- Prompt Specification
- Gateway parameters
The relationship among Gateway request, vendor request and LLM request can be depicted as below. As you can see, crucial part of GenAI Gateway’s job is to translate Gateway request to vendor request or LLM request:
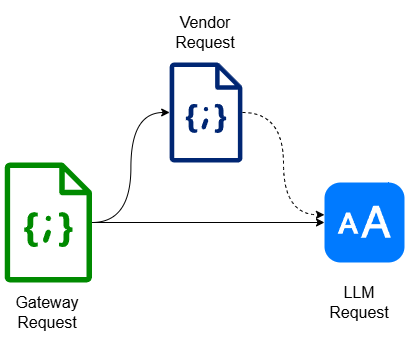
With terms around GenAI Gateway defined, we’re ready to examine closely on the “I“, “C“, “O” and “M” aspects of it.
3. Input
The interface of GenAI Gateway is defined by the endpoints as well as their payload structures.
3.1 Gateway Endpoints
Below is what a v1 GenAI Gateway endpoints looks like:
- /v1/direct-invocation. Invoke a model with a native syntax request.
- /v1/generation/text. Generate text completion for a given prompt.
- /v1/embeddings. Generate embeddings for a given input.
- /v1/guardrail. Invoke a guardrail model for a given input and optional context.
- /v1/batch. Submit a batch job.
- /v1/batch-status. Check status of a submitted batch job.
- /v1/models. List all available models or the subset of authorized models for the requestor.
Different endpoint support different types of model interfaces:
| GenAI Gateway Endpoint | Abstract Interface | Native Interface |
|---|---|---|
| /direct-invocation | X | |
| /generation/text | X | |
| /embeddings | X | |
| /guardrail | X | |
| /batch | X | X |
3.2 Endpoints payload structures
LLMs, embeddings or guardrails, request/response or batch, all involves model invocations. So, model specification is common to all GenAI Gateway endpoints and model parameters and gateway parameters are common to all endpoints except /direct-invocation:
{
"model": {
"provider" : "AzureOpenAI",
"id" : "gpt-4o",
"version" : "2024-08-06",
"type" : "text"
"pool" : "BU2"
},
"model-params" : {
"temperature" : 0.6,
"logprobs" : true
},
"gateway-params" : {
"return-assembled-request" : true,
"time-metrics" : true,
"response-filters" : ["content","total_tokens"]
}
}
As to input specification, /embeddings and /guardrail endpoints both accept a piece of text as input and /guardrail accepts an additional optional piece of text as reference/grounding:
{
"input" : "input text here",
"reference" : "optional reference text here"
}
The namesake /generation/text endpoint accepts below two elements which we’ll elaborate on next:
{
"prompt-spec" : {...JSON...},
"promot-template" : "template string to customize LLM prompt"
}
Last but need-to-be-built the first is the /direct-invocation endpoint in its entirety:
{
"model": {
"provider" : "SageMaker",
"id" : "Mistral-Finetuned-For-UseCase-D",
"version" : "2",
"pool" : "Dedicated-Pool-For-UseCase-D"
},
"request" : { Request JSON with structure that's native to Mistral }
}
3.3 Abstract prompt specification
Prompt structures from different vendors couldn’t be more different yet they all share the same set of concepts:
- System. Prompts that specify the persona of the LLM system. “You are a helpful helpdesk agent…”, “You’re an experienced financial advisor that’s good at explaining financial terms to laymen…”.
- World. Ground truth about the world the LLM system operates in. For RAG use cases, the retrieved contents would be the ground truth. The presence of worldly ground truth prompts the LLM system to operate with a “closed world” assumption.
- Tools. Functions the LLM system may call.
- Examples. Pairs of example correspondences between user and the LLM system. For few-shots in-context learning use cases, the example correspondence would be the context for the model to learn.
- Past messages. Histories of interactions between user and the LLM system leading up to user’s current message.
- Current message. User’s current message from which the LLM system continues and complete.
A vendor and LLM agnostic prompt specification could be a Bonafide copy of above list:
"prompt-spec": {
"system" : {},
"world" : {},
"tools" : {},
"examples" : {},
"past-messages" : {},
"current-message" : {}
}
But the vendors mudded the water with unnecessary and counterproductive “optimizations”:
- “past-messages” and “current-messages” are combined together as “messages“, you have to take the last message as the user question.
- User LLM system interaction “messages” are combined with LLM system prompt.
- “world” ground truth prompts are combined with “system” prompts.
If you remember that the Gateway prompt and vendor prompt are just containers of information that’s used to assemble the unstructured LLM prompt, you’ll agree with me that the more nuanced the prompt structure is, the more opportunities for the LLM prompt assembler to produce the optimal LLM prompt.
3.4 LLM prompt template
The translation from vendor prompt specification to vendor LLM prompts is done by the vendors. The translation from Gateway prompt specification to open source LLM prompt must be done by the Gateway. To that end, we could provide a template facility “prompt-template” which draws values from “prompt-spec” to afford LLM prompt customization:
{
"prompt-spec": {
"system" : "You're the best story teller.",
"world" : "Rolly pollies are aliens.",
"current-message" : "Where does rolly pollies come from?"
},
"prompt-template" : "{{system}} Based on below assumption:
{{world}} Answer below question: {{current-message}}"
}
With would produce below Mistral prompt:
“You’re the best story teller. Based on below assumption: Rolly pollies are aliens. Answer below question: Where does rolly pollies come from?”
As a testament to LLM’s touchiness, our data scientists found that asking the question before offering the ground truth produces much better completions. To achieve that, they simply change the “prompt-template” string to:
{
"prompt-template" : "{{system}} Answer below question: {{current_message}}
based on below assumption: {{world}} "
}
And the Gateway would produce below Mistral prompt:
“You’re the best story teller. Answer below question: Where does rolly pollies come from? Based on below assumption: Rolly pollies are aliens.”
This is why I enjoy tinkering with GenAI Gateway but not actual LLMs.
3.5 Prompt-spec message structure
LLM vendors don’t talk to each other, and each of them has the baggage of maintaining backward compatibility, and all of them are moving at a breaking neck speed. The end result is a mess of the different prompt structures we as consumers must deal with. Refer to appendix A for myriad ways to ask LLM to compare two images.
But with the additional layer of abstraction, we can take the sane road. For example, to handle multi-modal input, we could normalize the prompt structure to a flat list of quadruple of:
{"role", "content-type", "content-format", "content"}
- role. “user” or “assistant” (a.k.a., “model”,)
- type. The MIME type of the input data
- text/plain. (default)
- image/png
- image/jpeg
- audio/wav
- application/pdf
- …
- format. The format to parse the content field.
- utf-8. (default)
- uri
- s3-path
- base64
- …
- content. actual content payload.
For the multiple parts of one user utterance(text, image, voice), while vendors uniformly go down the nested path, we adopt a flat and normalized list structure. The change of ‘role’ in the list signifies the start/end boundary of an utterance. Hence our messages are order sensitive at the boundary but not order sensitive within each block.
"past-messages": [ # user prompt 1 { "role" : "user", # Mandatory "content": "Describe the differences between the two images." # Mandatory }, { "role" : "user", "type" : "image/png", # Optional: MIME type "format" : "uri", # Optional: format "content": "https://upload.org/ant1.png" }, { "role" : "user", "type" : "image/jpeg", "format" : "base64", "content": "iVBORw0KGgoAA...PnwvxA" }, # assistant response 1 { "role" : "assistant", "content": "The first picture contains an ant but the second one a piglet." }, # user prompt 2 { "role" : "user", "content": "Which one is heavier?" }, # assistant response 2 { "role" : "assistant", "content": "The piglet." } ] "current-message": [ # user question { "role" : "user", "content": "But which one is stronger?" } ]
3.6 Call for standardization
The prompt specification and its structures could and should be standardized. It shall be called OpenPrompt and vendors should be forced to adopt it. Again, my interest lies elsewhere but more than happy to volunteer my time on this endeavor.
3.7 Specify once, run on any LLM
With the LLM agnostic prompt specification, when another new and shinier LLM comes to town, you won’t need to change your client code much other than switching the model to the new-shinier-llm.
4. Control
To harden your GenAI Gateway to enterprise grade, it must have the standard bells and whistles for security, reliability, auditability…
- Authentication. OAuth and JWT tokens maybe used to prove the identities of the requester.
- Authorization. Fine-grained white list should be maintained to make sure the requestor has access to the requested model.
- Token rate limiting. Token based rate limiting to prevent abuse and overuse.
- Circuit breaker.
- Bulk heading.
5. Output (consumption patterns)
Real-time, async, request/response, batch… GenAI Gateway should support all different consumption patterns. Your data scientist and machine learning engineer consumers who are not necessarily strong in software engineering would appreciate these paved-path pattern off-the-shelf. From GenAI Gateway consumer’s point of view:
- Real-time consumption is for single request which is small in size and fast in processing time.
- Async consumption is for single request which is either large or slow. Async still is a request/response pattern and any vendor implementation imperfections such as additional S3 buckets and notification queues should be abstracted away.
- Batch consumption is for a lot of requests processed together.
5.1 Batch
Analyzing social media posts mentioning your products, generate embeddings for all the new documents added to your content library… Batch invocations of GenAI Gateway endpoints are a common pattern. Assuming the batch is homogenous in their structure and processing needs, a template based GenAI Batch runner can be built as below and exposed via GenAI Gateway’s /batch and /batch-status endpoint:
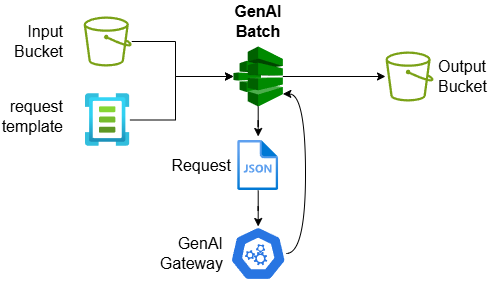
The key functional requirements for the GenAI Batch runner are as below:
- Input bucket contains one or more data files containing structured records.
- An ID field is specified to join the input and generated output data records.
- A template file lays out the GenAI Gateway request structure with template variables mapped to input data fields.
- JSON paths maybe specified to pick the output data fields out of the generated response.
- Output bucket mimics the file structure of the input bucket.
- Resiliency features such as exponential backoff, business hour scheduling and dedicated throughput pool in place to prevent batch job from interfering the real-time requests.
6. Mechanism
The provisioning of GenAI resources and the routing of requests to resources constitutes the mechanism aspects of GenAI Gateway’s functions.
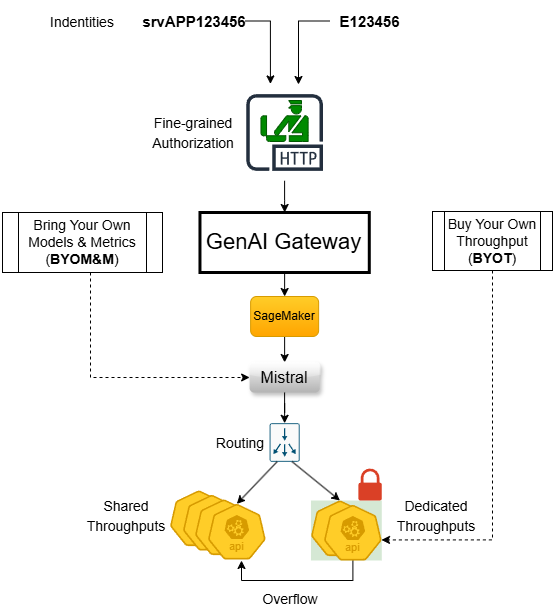
As illustrated in above diagram, a set of processes and MLOps pipelines must to be instituted to reduce your ops workload:
- Self-service process to allow practitioners to onboard models or metrics to GenAI Gateway.
- Self-service process to allow business owners to secure dedicated throughput pool.
- Automated MLOps pipelines to onboard vendor models.
7. Scaffoldings around GenAI Gateway
For GenAI Gateway to afford more utilities, it needs to be designed to play well with other components or players in the GenAI ecosystem.
7.1 LangChain integration
As yet another abstraction layer over the GenAI wonderland, hyped frameworks such as LangChain enjoys zealous following among those who can’t wait to embellish their resumes with it. They’ll inevitably ask for LangChain integration with GenAI Gateway and cry “we’re blocked!” even though they could perfectly use GenAI Gateway directly. As more and more LangChain fanboys choose to be blocked, it’s easier just to cave to their demands rather than deal with the explanations, pressures and noises.
But LangChain itself hasn’t figured out their design yet and it’s certainly not designed with enterprise grade use case in mind. Two sensible integration approaches work with the lowest and highest LangChain abstraction respectively:
- The adaptor pattern. Use GenAI Gateway to implement LangChain’s base classes.
- The bridge pattern. Provide a vendor API that LangChain’s top level classes expect.
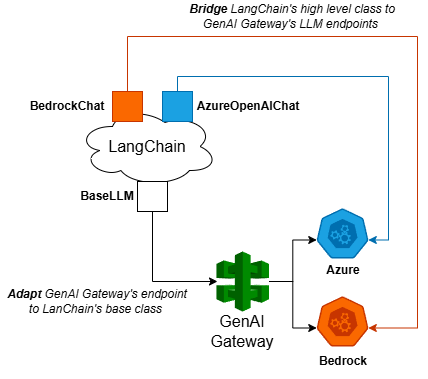
Either way, the key to remember is do not let requests come through LangChain bypass the GenAI Gateway’s control plane!
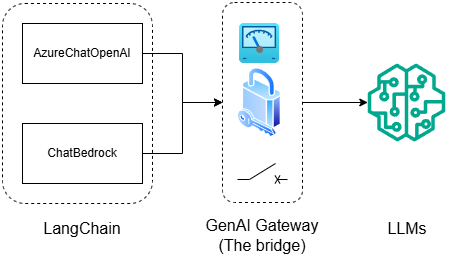
7.2 GenWise
With the congenital hallucinations and the non-monotonically increasing quality among newer versions, GenAI evaluation becomes another sought-after shovel in the GenAI goldrush. A trivial addon to GenAI Batch may satisfy 80% your GenAI Eval needs without doling out money to shovel sellers such as Galileo or Fiddler.
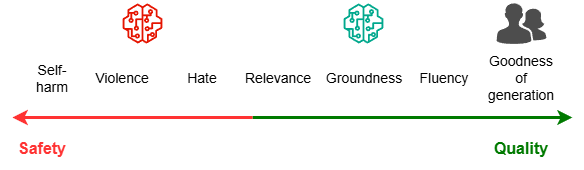
Before showing you how and why so, it’s beneficial for us to explicitly differentiate the two types of evaluative metrics as they should be handled differently:
- Safety metrics. How bad the prompt and generated text are? Violence, hate, suicidal… These metrics are readily available from open source or vendors and they preform pretty good. If you must buy, buy them from your cloud vendors rather than third party like Galileo to save the additional plumbing.
- Quality metrics. How good the generated text is? I’d like to contend that true goodness-of-generation metrics doesn’t exist and you must rely on human domain experts to judge whether or not one LLM outperforms the other. Don’t trust the published benchmarks, those man-made data sets most likely don’t align with your use case well!
With GenAI Batch and a Bring Your Own Metrics (BYOM) process which allows GenAI practitioners to define and onboard their own metrics, GenAI evaluation boils down to two batch runs and metrics calculation at the end of each run:
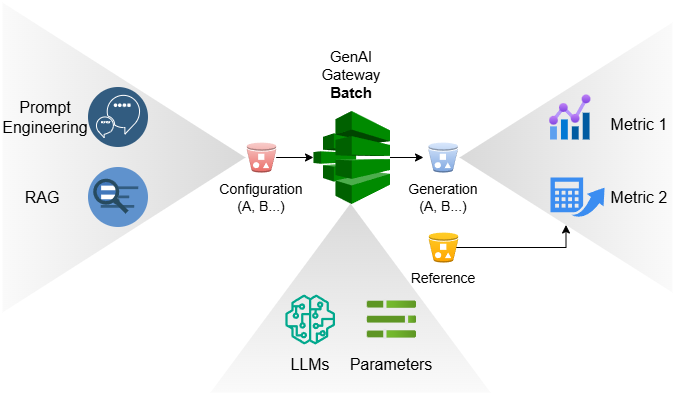
As you see, a GenAI evaluative framework is so simple to build on top of GenAI Gateway, you should just do it and shove it in the face of those who can only sing the tune of NSYNC’s ‘Buy Buy Buy’.
8. A layered architecture for GenAI Gateway
When it comes to implementation, organizing GenAI capabilities into functional layers which can be built, managed and operated independently will save you a lot of headaches:
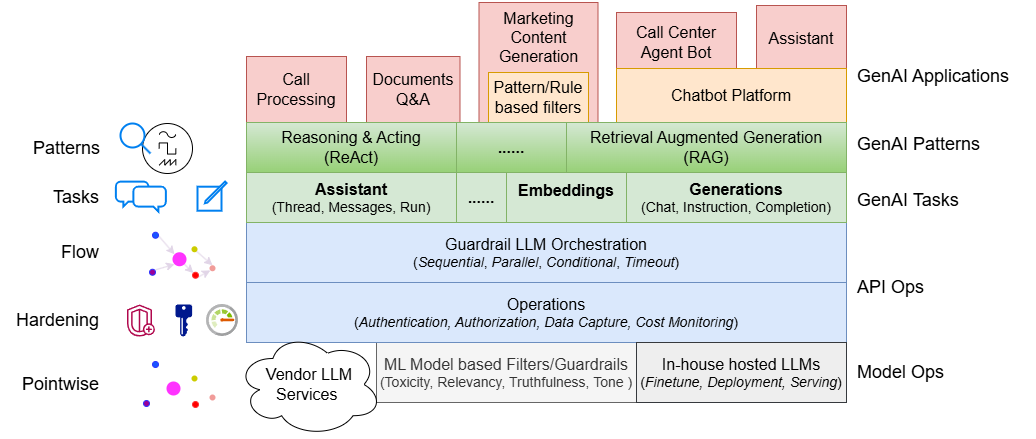
From bottom up:
- Model Ops layer. GenAI resources provisioned behind the GenAI Gateway. These include LLMs, embedding and guardrails models from in-house or vendors.
- API Ops layer. Operational tasks around APIs such as security, scalability and controls, as well as the capability to orchestrate multiple APIs into a flow.
- GenAI tasks layer. Functional interface exposing GenAI capabilities to consumers.
- GenAI patterns layer. Functional interface enabling GenAI patterns.
- GenAI Applications layer. Applications driven by GenAI capabilities.
GenAI Gateway should be open for GenAI apps to reach lower layers or add custom layers:
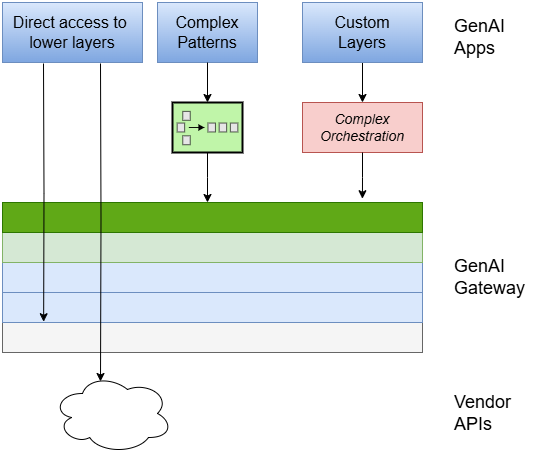
9. GenAI Gateway vendors
When it comes to build vs buy decisions for GenAI Gateway, you should realize that the most difficult pieces are already provided by the vendors, you just need to slap a couple of FastAPI endpoints on the top and call it your GenAI Gateway. The integration cost of buying from a vendor most likely out weight the development cost of building yourself. Still let’s look at several GenAI Gateway vendors out there anyway.
We evaluate GenAI Gateway vendor products along the following dimensions:
- Abstract interface. Does the GenAI Gateway provide syntactical abstraction over various backend LLMs? If yes, GenAI applications built on top of the gateway enjoy plug-n-play capability with newer LLM backends.
- Form. What forms of interface available?
- Enterprise Grade
- Security. What authentication and authorization mechanisms does the vendor offering provide?
- Observability. What logging or token/cost usage monitoring does the offering provide?
- Availability. What control mechanism does the offering provide for a reliable service?
- Open Source. Is the offering open source?
| Vendor | Abstract Interface | Form | Enterprise Grade | Open Source |
|---|---|---|---|---|
| LiteLLM | OpenAI format | Python SDK, HTTP | JWT Auth, SSO, Observability | Yes |
| AI Suite | Standardized interface similar to OpenAI | Python SDK | Not yet | Yes |
| Hugging Face Generative AI Services (HUGS) | OpenAI Format | Python SDK, HTTP | Not provided | Yes |
| BricksLLM | No | Python SDK, HTTP | Rate limiting, reliability, observability | Yes |
| Javelin | Standardized | Python SDK, HTTP | Access control, PII leak prevention | Yes |
| MLFlow | Yes | ?? | ?? | Yes |
Appendix. Vendor prompt-spec.message syntax for multi-modal input
OpenAI
"messages" : {
"role" : "user",
"name" : "n/a",
"content" : [
{ "type" : "text",
"text" : "Describe the differences between the two images."
},
{ "type" : "imgae_url",
"image_url" : {
"url" : "https://my.image1.png",
"detail": "high"
}
},
{ "type" : "image_url",
"image_url" : {
"url" : "https://my.image2.png",
"detail": "low"
}
},
{ "type" : "input_audio",
"input_audio": {
"format" : "wav",
"data" : "iVBORw0KGgoAA...Pnw"
}
}
]
}
AWS Bedrock
Refer to Bedrock Converse HTTP API and Converse Python SDK Examples for details.
Unlike other vendors such as Azure OpenAI Python SDK, AWS Bedrock Python SDK expects raw byte array rather than base64-encoded strings, yet another polyfill we had to make to provide uniformed experience with our GenAI Gateway’s abstract HTTP API.
"messages" : [
{
"role": "user",
"content": [
{
"text": "Describe the differences between the two images."
},
{
"image": {
"format": 'png',
"source": {
"bytes": image_bytes1 # Bedrock Python SDK expects raw image bytes!!!
}
}
},
{
"image": {
"format": 'png',
"source": {
"bytes": image_bytes2
}
}
},
{
"document": {
"name": "MyDocument",
"format": "pdf",
"source": {
"bytes": input_document
}
}
}
]
}
]
Claude
import base64
import httpx
image1_url = "https://upload.org/Camponotus_flavomarginatus_ant.jpg"
image1_data = base64.b64encode(httpx.get(image1_url).content).decode("utf-8")
image2_url = "https://upload.org/Iridescent.green.sweat.pig1.jpg"
image2_data = base64.b64encode(httpx.get(image2_url).content).decode("utf-8")
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": image1_data,
},
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": image2_data,
},
},
{
"type": "text",
"text": "Describe the differences between the two images."
}
],
}
],
)
print(message)
Google Gemini
Refer to Gemini Doc for details.
"contents": [
{
"role": "user", # "user" | "model"
"parts": [
{
"text": "Describe the differences between the two images."
},
{
"inlineData": {
"mimeType": "image/jpeg",
"data" : "iVBORw0KGgoAA...Pnw"
}
},
{
"fileData": {
"mimeType": "image/jpeg",
"fileUri" : "https://my.image1.png"
}
}
]
}
],