(First created: 07/31/2024 |Personal Opinion)
In earlier posts, I have pondered over analytic experiences (AX) and what an ideal analytic platform entails to deliver great AX. Recently my mind has been on machine learning experiences. Impossible to reduce to two-letter abbreviations like its siblings such as DX (developer experience), UX (user experiences) and CX (customer experience), let’s stick with MLX for now.
In this treatise, we first review the wild, wild west of AI/ML tooling on the outside and the chaotic scene on the inside of a typical corporation, which gives you a sense of the pain points experienced by everyday ML practitioners in majority of the enterprises. We then imagine components of an idealized ML platform and the platform-engines-portal delivery triad for a great ML experience.
To begin with, by enterprise I have in mind the 95% of the traditional corporations of any industries and sizes, as long as they have any kind of data: from the small community hospital system in Cleveland Ohio, to the large intercontinental agricultural products company in Germany. Another way to put it, as the honest but painful reality, the Third World of AI. What I’m not talking about are the 5% big techs such as OpenAI, Meta and Google whose ML practices are a totally different game. For AI/ML tooling vendors who think themselves are in the know of AI/ML, the 95% of the enterprises who don’t know or lag behind accounts for probably 85% of the addressable market. So, you should be financially incentivized to read on to understand how to empathize and serve the not-in-the-know majority ML practitioners better.
The Wild, Wild West of AI/ML
After two harsh AI winters, in AD 2023, a new AI/ML frontier emerged behind a 175-billion parameters behemoth called chatGPT. People from all walks of life abandoned their old settlements and began over with large language models (LLM). Chief among them are the natural language processing (NLP) folks, the computer visionaries (CV) and the digital arts creatives, but you can also see strange fellas such as stock day traders and time series forecasters, wishfully dreaming that the inherently next token predicting LLM will give them an edge in their number games.
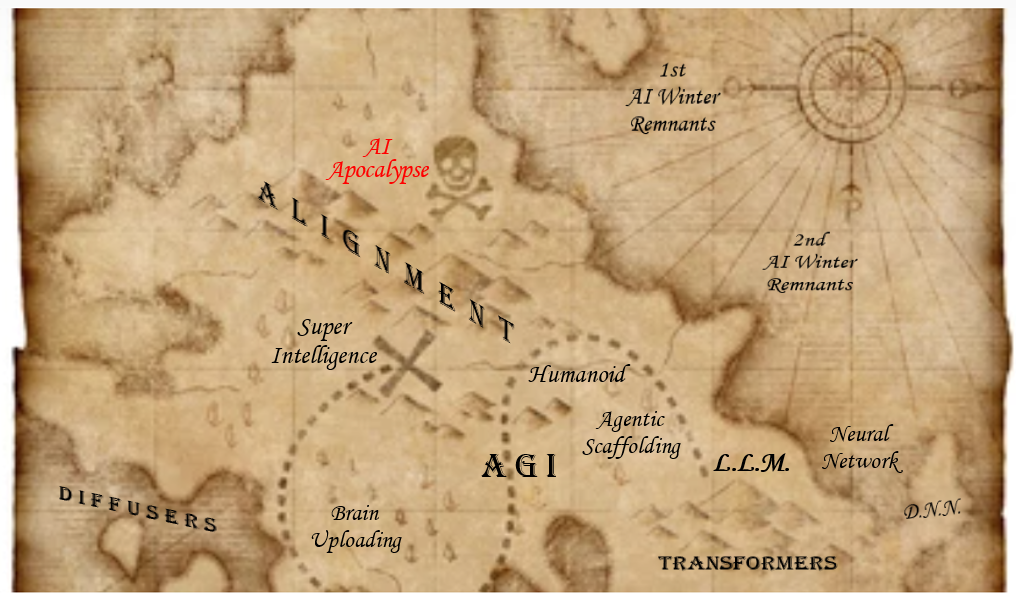
The gold rush and the shovel network
The news that machine learned models worth more than gold brought approximately all of the enterprises onboard the business of machine learning. Successes are abundant, but more saw their resources and energies wasted. Regardless of the success or failure of individual machine learning endeavors, there is one business that’s always winning: the machine learning tooling industry. It is so successful that unlike the simple picks and shovels during the gold rush, machine learning tooling evolves into an intricate multi-layered network itself, much like the deep neural network that give the industry life.
Click on the image to see the full-sized version and click “Back” button of your browser to go back to this page.
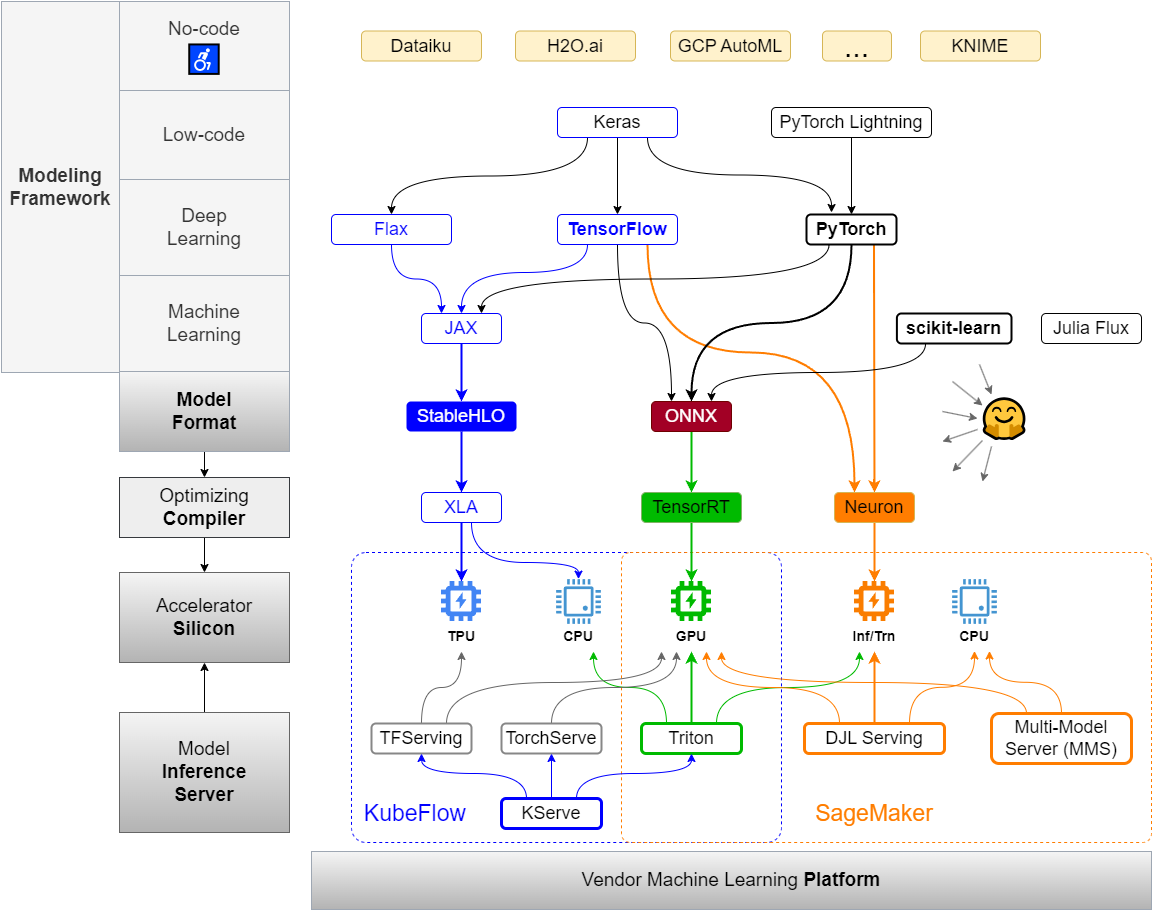
Several points on the above diagram worth noting:
The Color Coding:
- Blue. Google, where most AI/ML innovations originated from.
- Green. Nvidia, King of accelerator silicon, making an entry into the enterprise AI platform.
- Orange. AWS. First mover of cloud computing and managed AI/ML platform. Customer obsessed with dedicated account managers. AI/ML lagger and “Just Take It” perpetrator.
The Struggles and Politics:
- ONNX. Everybody else banded up to battle Google’s dominance in AI/ML.
- Nvidia + AWS, but not GCP. Nvidia does not perceive AWS Inferentia silicon as a threat, but not the case with Google’s TPU.
The Pain points:
- The choices paralysis. What are the optimal choices among all the available options for my data, my model and my use case?
- The boring plumbing. The myriad paths downward from the point the model is trained and inference code written, to the point the model delivers business values, are plumbing that’s boring to the math-minded ML practitioners.
ML Models as gold
Data permeates the enterprise like digital sand, ML models are learned from data like gold sifted from sand.
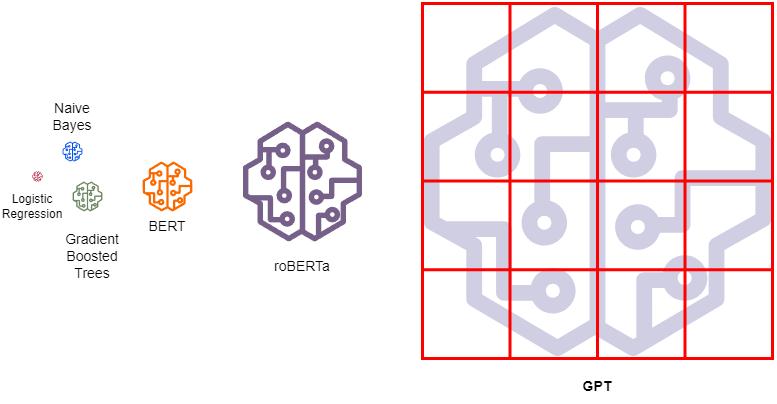
No one-size fits all
Tiny models such as Logistic Regression and Naïve Bayes can still be effective for many use cases. Large Language Models (LLM) which must be partitioned and loaded on multiple machines and many GPUs are much more complex and costly to train and serve.
No model is an island
Principle of locality (locality of reference) applies to model deployments where a set of models are better deployed together on one box for functional, operational and cost-saving reasons. An additional “dummy model” which is a workflow among the co-located models on the same box saves all the network hops should the workflow be deployed outside the box.
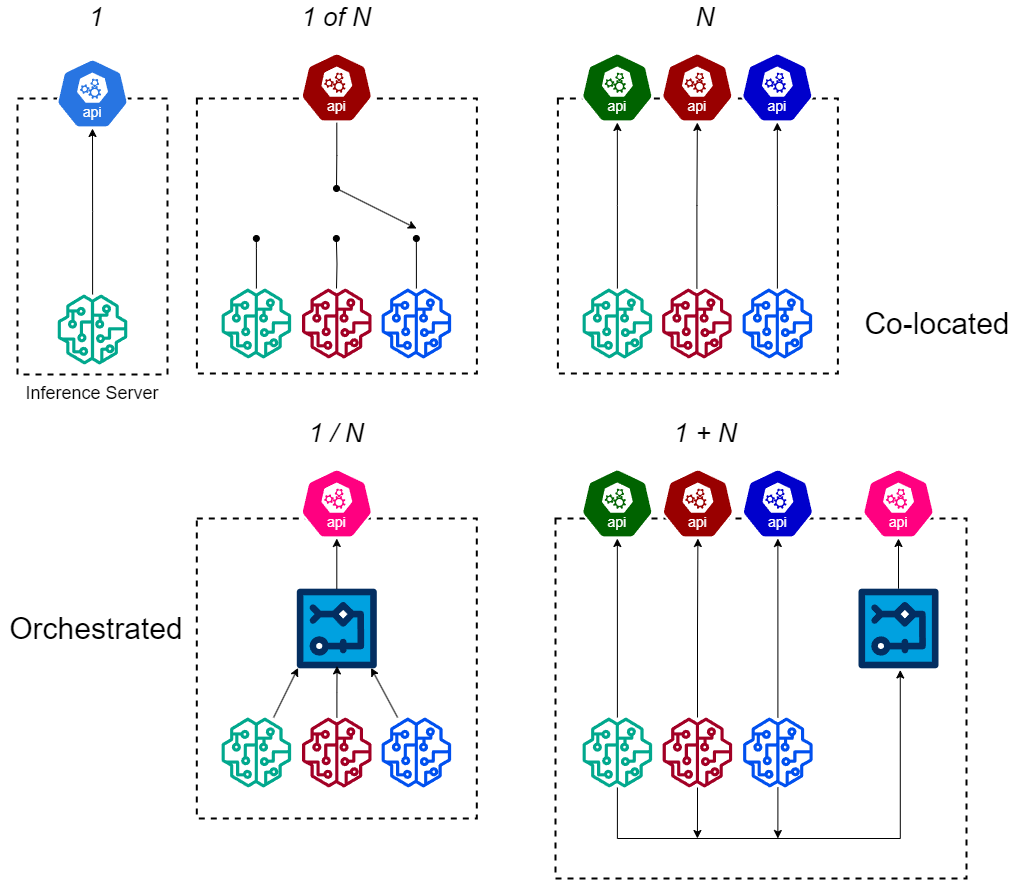
As shown in above diagram, colocation and orchestration among multiple models are the two essential functional requirements for various model deployment topologies. I encourage our industry to adopt the naming conventions proposed here or come up with better ones rather than churning out confusing and lousily named vendor specific names:
- AWS’ multi-model endpoints, multi-container endpoint and Nvidia Triton’s Model Repository are different implementations of model co-location.
- Nvidia Triton model inference server’s Model Ensembles and AWS DJL Serving’s Workflow Model (note not Model Workflow!) are implementations of model orchestration.
Workflow at all levels
Like in-database analytics, workflows can be pushed onto the model inference server to minimize network IO. Even when workflows live on a separate box, there is opportunity for optimization when all nodes of the flow are API calls. It’s beneficial to differentiate and define three different types of workflows:
- Model Workflow. All nodes of the workflow are model inference calls.
- API Workflow. All workflow nodes are API calls. Some API calls are model endpoints.
- General DAG workflow. In addition to API calls, there are custom code nodes in the flow which calls for provision of compute, scheduling and orchestration of their executions.
Orthogonally in relation to the model inference server, workflows may live on or off the inference server:
- On-inference-server. Workflows running on the model inference server. Model inference calls don’t need to be RESTful API call in this case.
- Off-inference-server. Workflows running on a different box than the model inference server. Model inference need to be wrapped in an API call.
With three different workflow types and on/off inference server deployment, we got six different combinations, not all of them makes sense:
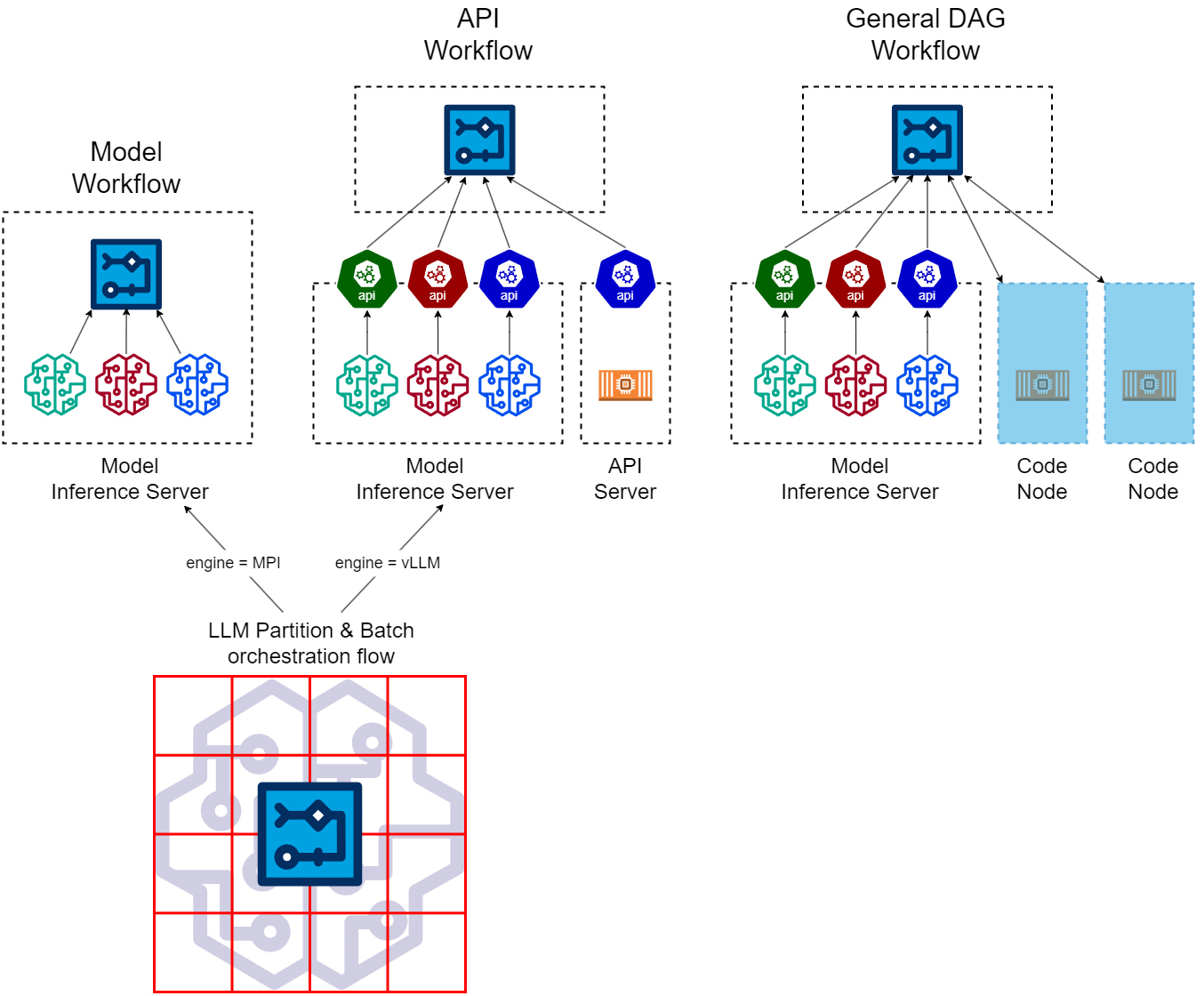
Some notes with vendor offerings:
- SageMaker Workflows support its own Model Building Pipeline (which can be abused to do multi-model inference I guess), Kubeflow Pipelines as well as general purpose DAG workflow tools such as Apache Airflow and AWS Step Functions.
- Nvidia’s DALI data processing pipeline can be run as a (dummy) model on its Triton inference server.
The Busy, Busy Town of the Enterprise
Inside the walls of any enterprise, it’s next to impossible to distant oneself from AI/ML. The pressure of associating whatever you’re doing with AI/ML is both bottom-up and top-down. The hustle and bustle of AI/ML turns the once sleepy enterprises into the busy, busy towns.
The ML tools industry is profiting but the towns are chaotic, costly, duplicative, full of politics producing only scant amount of proven business values, because the majority of the enterprises don’t know how to properly do AI/ML:
- Red tapes are all around. Legal Risk Compliance (LRC), Institutional Review Board (IRB), Politically Correct Police (PCP)… Countless AI/ML innovations are distracted or forced to go underground.
- Caliber of talents elicits frown. How many heads of AI/ML have read and understand the Attention Is All You Need paper? How many ML scientists know and have constructed a deep neural network architecture layer by layer, custom designed for their data and business problem at hand? The AI/ML domain is intrinsically technical, deeply. No matter how smart you are, intuition and copy-cat “hands-on” experiences just aren’t enough to make use of AI/ML at the most effective level. Since most of enterprises can’t or aren’t willing to pay for the top-notch talents with formal education in AI/ML, they stick with subpar AI/ML boot-campers and data engineers or business analysts turned ML “scientists”.
- Mazes and pitfalls abound. AI/ML scopes are such a hot commodity that they’re divvied up and handed out across the unorganized org-chart. Screwed up are the ML practitioners who don’t know who to talk with to get things done.
- Experimentations and measurements are rare to be found. Because of the lack or difficulty of conducting experiments and measuring business values, AI/ML cost-benefits analysis becomes a guessing game or lip service.
I can go on and on with what’s wrong in typical enterprise AI/ML practices, but don’t take me wrong, I’m only empathizing with the AI/ML practitioners. I’ll elaborate on three concrete components to illustrate the pain points of an enterprise AI/ML practitioners:
- Platform of choice. Practitioners are asked to work on top of counter-productive AI/ML platform.
- Business processes. Practitioners are asked to follow confusing and painful processes.
- Last mile delivery. Practitioners are held accountable to make business users happy without the means to do the last mile delivery easily.
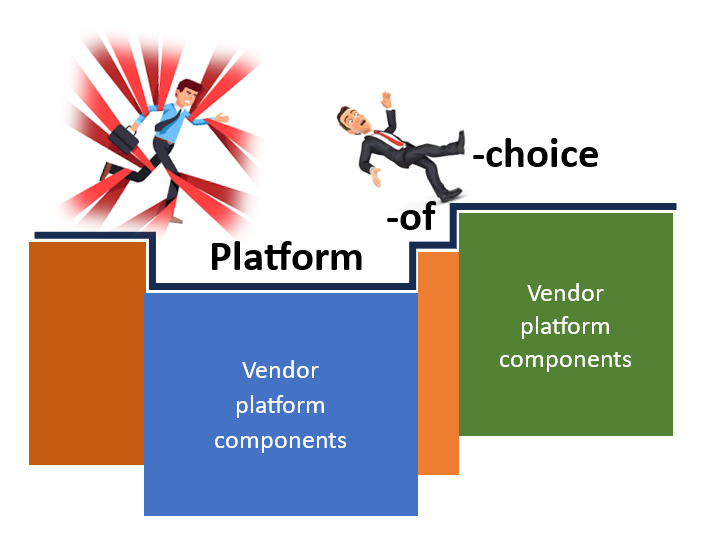
The AI/ML platform of choice
Unlike big techs who build their AI/ML platform from scratch, ordinary enterprises purchase commercial or adopt open-source platforms. The choices of vendors and open-source platforms are not always optimal:
- Handicapped choice. Call me discriminative but no/low code AI/ML solutions should never be the foundation of any enterprise AI/ML platform. If you drink the cool aid of Auto-ML or Driverless-AI, your machine learning team will never get the chance of maturing up. No/low code solutions as productivity tool for tasks such as data exploration? Maybe.
- Unrealistic choice. On the other end of the extreme from the handicap choice, a tiny ML platform team, under the leadership of an open-source zealot, tackles the complex task of building from scratch on top of Kubeflow. Management was sold on the cloud-agnostic and cost-saving double visions but the ML practitioners couldn’t even deploy a trained model after 10 months of wait. Managed solutions such as AWS SageMaker would’ve taken only weeks to onboard to. But why the mishap? The management wasn’t presented with and doesn’t know the alternatives.
- Incongruent choice. Better than software development community, the AI/ML folks are still tribal in what tools to use. The economic buyers of the enterprises are still at the mercy of political plays such as if you don’t buy our AI/ML solutions we won’t use your health insurance plan. As a result, multiple incompatible stacks of AI/ML solutions exist under one roof, hindering common and core sharing.
When a workflow contains one or more nodes of manual tasks, it becomes a business process. While governance and controls are all necessary, red tapes, politics, delays, mistakes… the humans in the loop are all sources of frustrations:
- Before training, an institutional review board (IRB) need to review and approve the data and training plans of models.
- Before production deployment, MLOps engineers need to review model’s performance test results and approve the requested compute instance size.
- Production endpoints can only be handled by MLOps team members, whom are typically overwhelmed with requests.
Further exacerbating the pain, in the name of streamlining the business processes, an incohesive tapestry of tools and systems are put in place for you to navigate:
- One needs to file intake forms with different teams in different formats: Jira story, Excel spreadsheet, web forms, Teams channels…
- One might be asked to go out of way and run a Jenkins job here and operate an awful self-service tool there.
- To expedite a request, one is forced to join the Team’s office hour and talk to a human.
The last mile delivery
You trained a model, now what? Every morning at 8:00am, the nurses are waiting for your model’s ranked list of at-risk patients to make the phone call. The primary care physician is expecting your model to alert her that the patient she’s seeing has an uncaptured HCC code. To activate your model, you need to:
- Plead the data engineering team to develop and deploy the ETL pipelines.
- Beg the IT team to establish the secure file transfer process for the PII ranked list of patients.
- Work with the electric health record (EHR) system team to have your model endpoint integrated.
All of above cross-functional dependencies are outside of your control. If you desperately need the impacts of your model to secure your long overdue promotion, good luck.
The Ideal Machine Learning Platform
With the breakneck pace of advancement in the AI/ML space and the lackluster maturity of enterprise AI/ML practice, there’re always endless amount of work to be done to boost ML practitioner’s productivity. I recommend to start with machine learning platform.
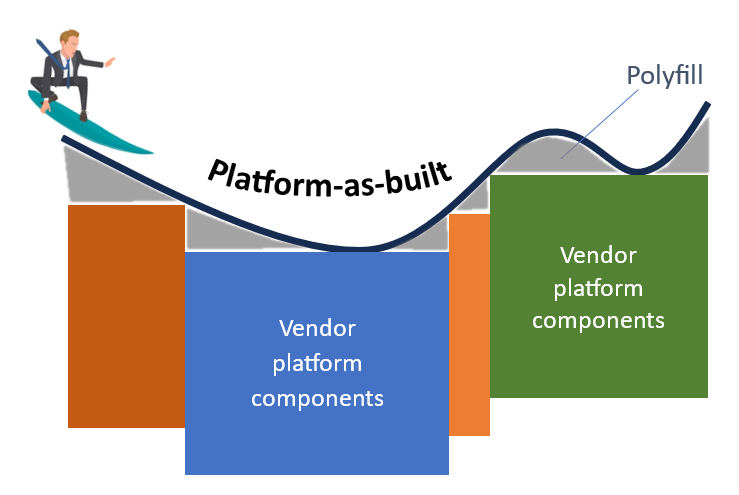
ML Platform-as-built
Experientially, ML platform-as-built should be as smooth as possible with custom-built polypills filling the gaps among vendor components.
Procedurally, ML platform-as-built supports general ML flow across all business units (BU):
Click on the image to see the full-sized version and click “Back” button of your browser to go back to this page.
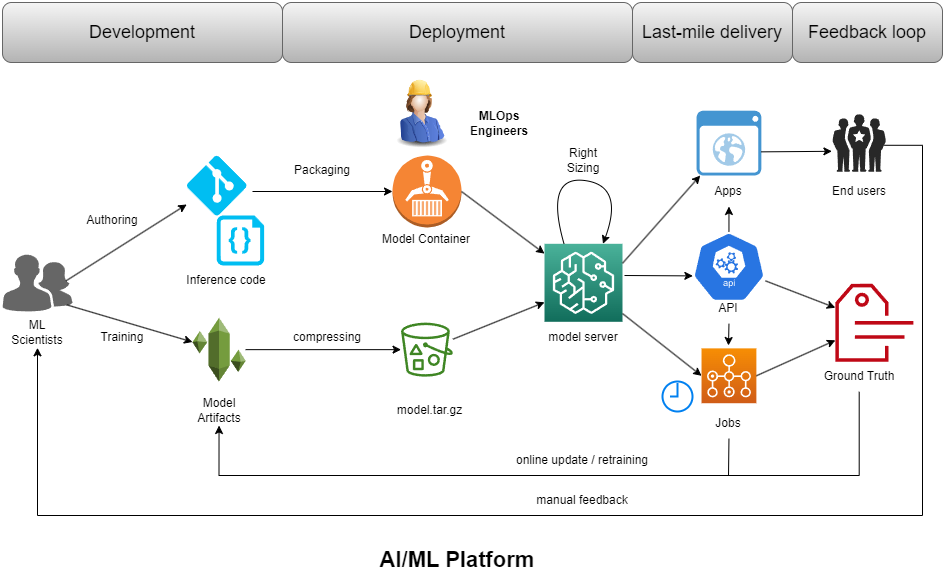
Functionally, ML Platform-as-built should provide maximum support every step along the AI/ML lifecycle: Data engineering, feature engineering, feature store, model training, model offline/online testing, model deployment… To avoid repeating the well-knowns, I elaborate only on the few AI/ML platform components that’s typically overlooked:
- Model Maker. Tools and framework to help packaging and deploying models.
- App Maker. Tools and framework to help developing, packaging and deploying apps for last-mile-delivery.
- Solution Engines. Scaffolded compute engines solving for specific kind of problems in a specific vertical domain: customer phone calls, scanned documents, emails…
Model Maker
We mentioned that AI/ML practitioners are tribal when it comes to languages, frameworks and development environments, it’s better to leave it to them to pick and use their favorite tools for modeling and training.
But once the model is trained, the mundane work of compiling, packaging and deploying with different inference servers on different clouds could and should be automated. ML Practitioner should only need to focus on the model artifacts and inference code, the rest is handled by Model Maker.
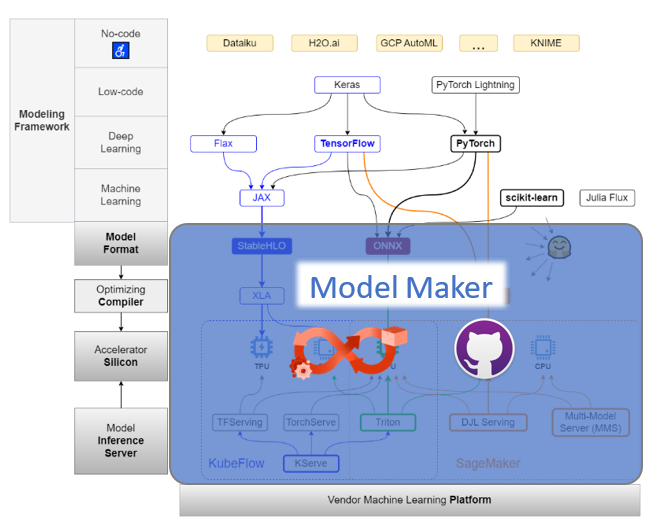
Model Maker should also offer necessary tools for each step along the model making process:
- Performance testing tool, to make sure latency satisfies expected SLA.
- Load testing tool, to choose the right instance type for the model endpoint.
- Experimentation tracking tool, during process of hyperparameter tuning.
App Maker
The cross-functional pain of the last mile delivery could be eliminated by empowering ML practitioners to take it into their own hands. App Maker is an Pythonian rapid development framework for all the pieces that are needed to develop and deliver the end user experiences:
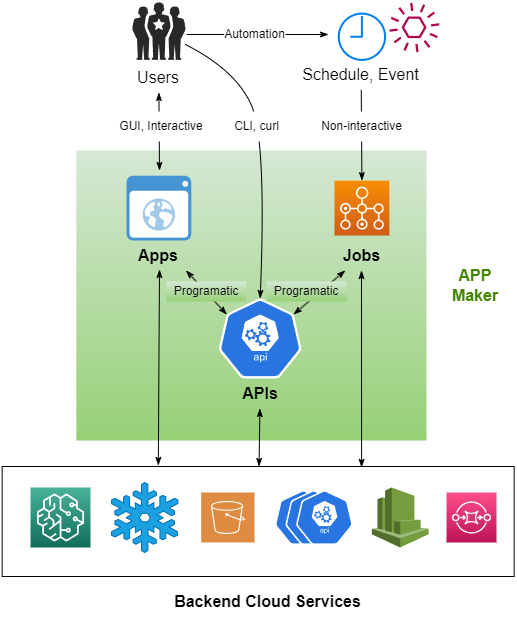
Majority of the last-mile delivery needs can be satisfied by below type of apps:
- Interactive web apps. For interactive end-user experiences, Pythonian web app frameworks such as Streamlit, Gradio and Dash can be wrapped inside App Maker.
- APIs. For programmatically accessed APIs, framework such as FastAPI can be wrapped inside App Maker.
- Jobs. ETL pipelines and maintenance tasks can be automated as scheduled or on-demand batch jobs.
App Maker should be code first and operates in the gitops fashion.
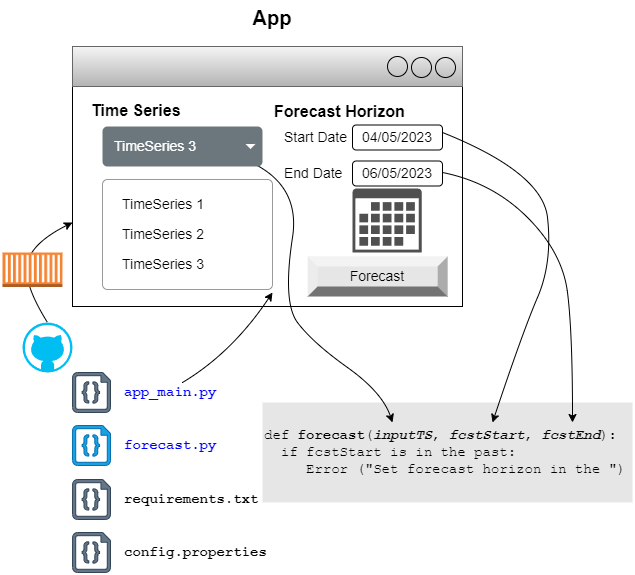
App Maker can be used to develop not only AI/ML but any experiences Python ecosystem supports.
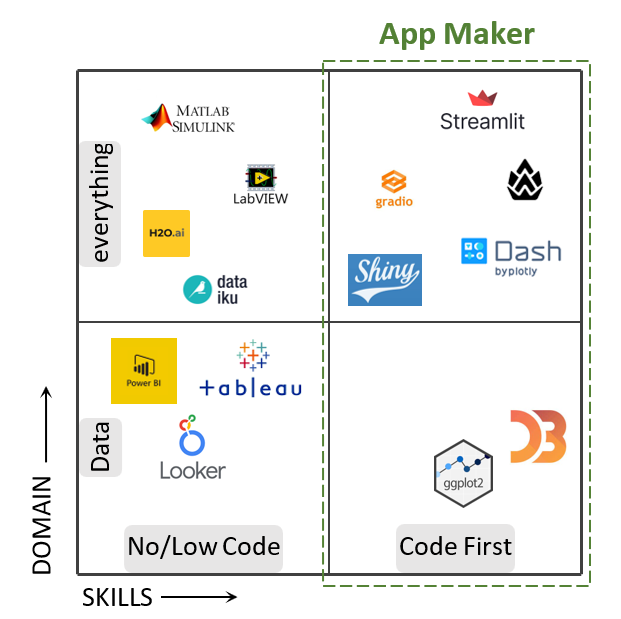
With App Maker taking away the plumbing such as packaging and scalable cloud deployment, ML practitioners can be productive at end-user app making.
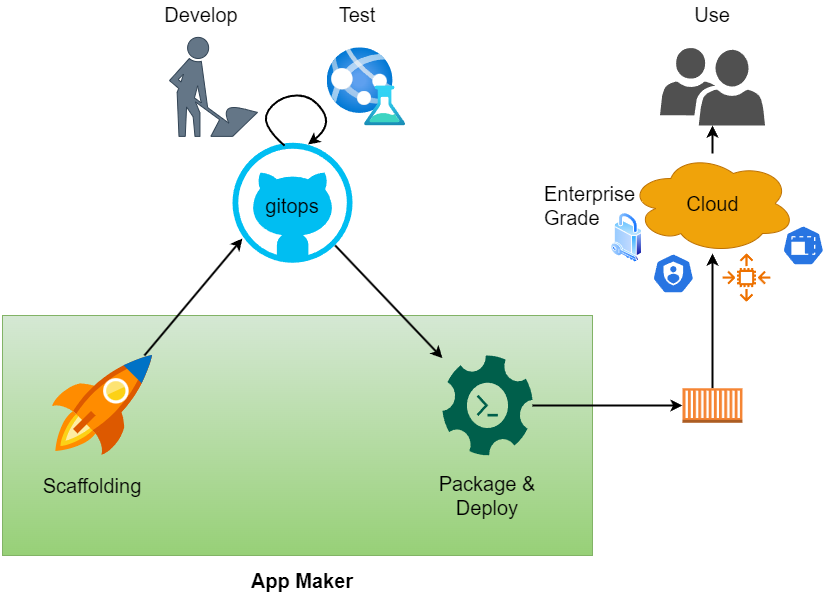
App Maker should be enterprise grade. SSO integration, role-based access control, rate limiting, bulk-heading, CI/CD, auto-scaling… ML Practitioners get these goodies for their apps out of App Maker for free. Gone are the days when security or architect forbid data scientist’s Streamlit app from deployment because they’re not secure.
Solution Engines
Model Maker and App Maker are components of the AI/ML platform which serves common needs of AI/ML practitioners horizontally across business boundaries and domains. Ideally there should be only one ML platform at the enterprise level, rather than duplicated platforms within each business unit (BU).
Same principle applies to common solutions patterns in vertical domains, such as:
- Call processing. Voice-to-text transcription, PII masking, NLP tasks such as sentiment, topic analysis and named entity recognition (NER)… All phone call data, regardless where they’re originated from, need the same set of processing capabilities.
- Documents processing. Forms, receipts, scanned legal documents… OCR, landmark detection, form classification… All documents need to go through the same set of processing steps.
- GenAI Gateway. LLM, guardrail, RAG, agent scaffolding… Authentication, authorization, token-based rate limiting… Any GenAI application requires the same set of capabilities around LLMs.
It makes sense to develop these common capabilities into domain specific processing engines, with below functional and operational requirements in mind:
- Real time and batch modes. The same processing workflow should be made available in both API and batch processing forms.
- Compute storage separation. The data that flows through the engine as well as the input/output storage are owned by the solution team that make use of the engine. This enables centralized innovations in the engines as well as diverse data governance, compliance and operational patterns by consumers of the engines.
The Experience Layer: AI/ML Practitioner’s Portal
ML Platform are only useful if it’s well documented and supported. Automated workflows deliver business values only if people know and use them. The enterprise town calms down only if common and core capabilities as well as paved paths are shared and reused. All these concerns call for an experience layer that put forth the right people, process, tool and knowledge at the fingertips of the ML practitioners right when they need it, so they can tap into them and get things done with a pleasant experience. The experience layer should strive to achieve below goals:
- Single provider of experience. Data, features, models, API endpoints, apps, jobs… cleansing, ETL, selection, reduction, train, deploy, monitor… data engineer, ML engineer, ML scientists, business analysts, product owner, business user… All types of ML artifacts, activities and actors should be covered by the one and only portal.
- Minimized modes of operation. If things can be done with a web experience, provide it within the portal. SageMaker Studio, Jenkins Core, ServiceNow… don’t let me hop around multiple systems. Docker container, Jyputer Notebook, Jenkins job, Python scripts, Streamlit app… don’t let me get different tasks done in different modalities of operations.
- Personalized experiences. AI/ML practitioners from different business unit (BU) with different roles should have different views and receive different experiences.
- Eliminate human touch. Build automated workflows in place of human-in-the-loop business processes as much as possible.
- Decouple human touch. If the humans in the loop can’t be automated away, invest in a ticketing or business process management system with which tasks can be managed, governed and monitored asynchronously.
- Foster ML culture. Buy vs build, empire building vs common-and-core, exploration vs exploitation… A culture that’s fit the reality of an enterprise can be fostered by the components and configurations of the experience layer.
With these goals in mind, the experience layer can be partitioned into below functional areas:
- The work-bench. Everything about development.
- The cock-pit. Everything about operations.
- The market place. Everything around artifacts.
- The community center. Everything about people socializing.
The work-bench
Capabilities supporting development activities for all types of ML artifacts are organized around the work-bench:
- Integrated Development Environments (IDE) with git ops integration
- CI/CD pipelines
- Tools for experimentation tracking and A/B tests.
- Tools for performance, load and chaotic testing
- Tools for documentation such as static site generation
- Deployment schemes such as feature flags, canary, roll back.
- Streamlines processes for governance: review, approval, registration…
The cock-pit
Capabilities supporting operational activities for all types of ML artifacts are organized around the cock-pit:
- Monitoring of health, drift, cost, quality and business metrics
- Alerting and incidents on degradation, drift and failures
- Logging.
- Tracing.
- Direct manipulation mechanisms to change the state: adjusting auto-scaling policy, decommissioning an unused costly model endpoint…
- Necessary manual business processes or automatic workflows are triggered to achieve the desired state.
All above enables the reliable operations of AI/ML solutions through the define, measure, analyze, improve and control (DMAIC) process.
The market place
Capabilities supporting ML artifacts governance, discovery and sharing:
- Ontology defining concepts and relationships among all types of ML artifacts.
- Tagging of ML artifacts with terms defined in the ontology.
- Catalog of ML artifacts.
- Search over the catalog.
- Visualization facilitating browsing of the catalog.
The community center
Capabilities supporting collaborations among ML practitioners with all types of roles:
- The Bible. Knowledge, best practices shared in forms of blogs, tutorials, playbooks, training courses, recordings…
- The social network, among internal ML practitioners.
- Chats. Direct messaging among ML practitioners.
- Events. Social gathering of ML practitioners.
Bringing all together
If we accept the premise that the customer is God, ML tooling industry should put ML practitioner’s experience above all.
ML Experience as a façade
With a solid platform as foundation, a set of scaffolded compute engines to prop up the vertical solutions, and a portal delivering smooth experiences, the wild, wild west of AI frontier and the busy, busy enterprise town retreat to the background, and the AI/ML practitioners may focus on getting things done.
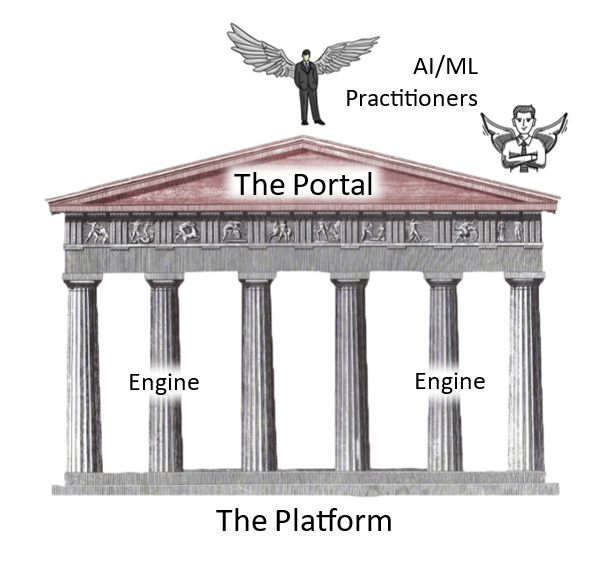
ML Experience as a shell
On-prem vs cloud, built vs bought, legacy vs future proofed, enterprise vs business unit levels… the experience layer must towner over the hodgepodge of whatever the enterprise reality is. The most efficient way of doing that is via APIs. Even the oldest dinosaur system has learned to prop up a micro-service to integration with other systems by now. With the API layer abstracting the nastiness and complexities of the enterprise realities away, the experience layer may focus on crafting what it meant to do the best: experiences. From this aspect, the experience layer to ML practitioners is like a shell to a operating system.
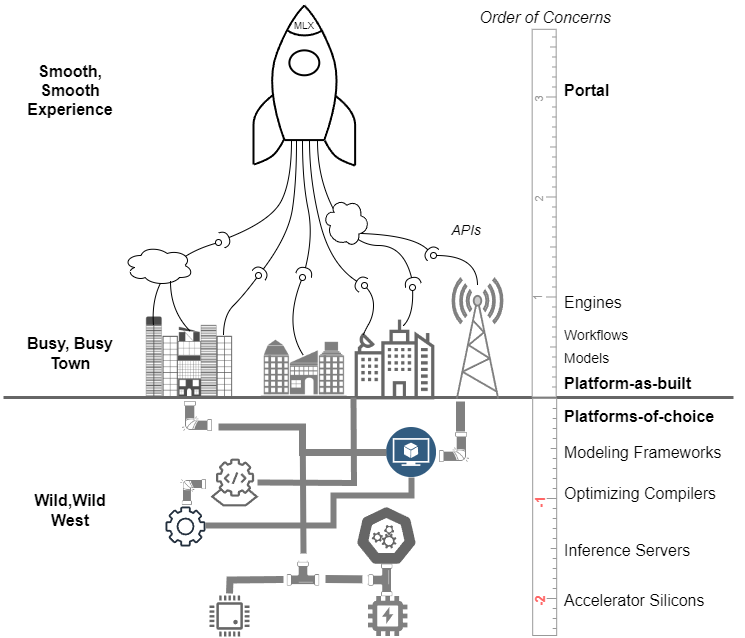
ML Experience on a ladder
The ‘order of concern‘ level marker shown in above diagram indicates the severity of pain everyday ML practitioners face in an enterprise environment. The higher the order, the painful the experiences are. On the negative side, those underground stuff are NOT a concern to them. They’ll use whatever big techs or open source come up and switch to the better ones without hesitation or guilt. If you’re not selling compute, there is no money to be made there.
The ladder also indicates the size and profitability of opportunities for improvement. Less providers are addressing the high orders concerns and they’re technically low hanging fruits to pick. Case in point, the ‘One click deployment of models to production’ feature eliminates all the painful paper work, the meetings with the MLOps team and the long wait, yet it’s trivial to build.
Unfortunately many AI/ML tooling providers work on the wrong things that ML practitioners don’t need and care because:
- They cannot empathize with everyday ML practitioners. Probably because they never set foot in a non-big-tech enterprises and don’t have the lived experiences of everyday ML practitioners.
- They are drawn to the harder things. Model compilers, dynamic batching on LLM inference server… these underground concerns are interesting and challenging to work on but irrelevant to everyday ML practitioner’s experiences.
Parting words
There you have it, the current landscape and a vision for machine learning experience. Depend on who you work for and where your interests are in the AI/ML ecosystem, you may work below or above the ground, and prioritize up or down along the order of concerns ladder.
References:
- What is and why developer portal? Spotify’s Backstage 101.
- PyTorch vs JAX | Hacker News discussions
- Equinox, a PyTorch like JAX library | Paper
- GPGPU software: CUDA, Triton, Mojo
- Triton: paper | Github |
- Deploy Multi-model endpoints with DJL Serving
- Codegen dialects relationship graph